Member-only story
Azure Synapse Analytics Workspace— the tool unifies your Big Data Components

Azure Synapse has brought together Microsoft’s enterprise data warehousing with Big Data analytics. And the Azure Synapse Workspace is providing an unique experience by unifying various components into a common user friendly interface.

In this blog, we’ll evaluate the main components to some extent and will draw a simplified architecture.
Setting up an Azure Synapse Analytics Workspace
To start with, we’ll first create a workspace using Azure portal.



Glimpse of the Workspace
Once the workspace has been created, we’ll use the Workspace web URL to launch it in another browser window.
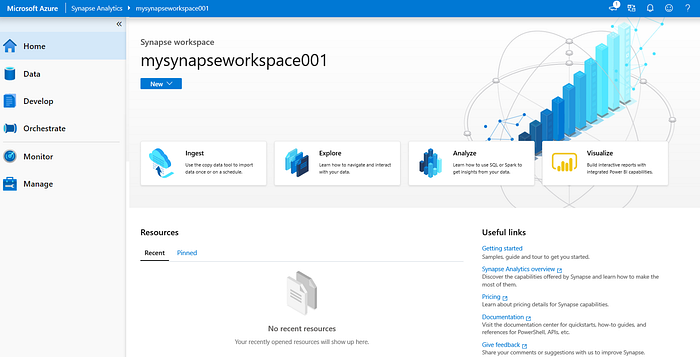
Synapse Analytics Workspace supports three types of ‘Databases’ — SQL pool, SQL on-demand and Spark pool. The Data > Workspace tab contains the database details. We’ll explore each type, to some extent in this blog.
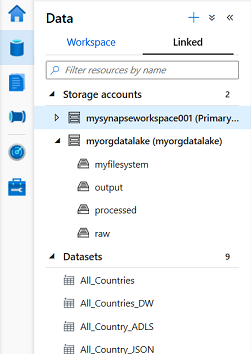
In the Data > Linked tab, we can add Azure Cosmos DB MongoDB & SQL APIs & Azure Data Lake Storage Gen 2. The primary storage account will be…
