PinnedProsenjit ChakrabortyChatting with your Analytical Data using OpenAI & LangChainCreating a chatbot on analytical data - highlights, limitations & observations.·18 min read·Nov 29, 2023----
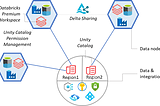
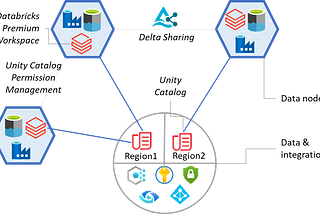
PinnedProsenjit ChakrabortyDatabricks Unity Catalog — all you need to knowEssential features of Unity Catalog with insights on how to seamlessly integrate it into an organization’s workflow.·13 min read·Jul 26, 2023--4--4
PinnedProsenjit ChakrabortyDatabricks — Delta Live Tables, Job Workflows & Orchestration PatternsDelta Live Table Pipelines, Auto Loader, DQ checks, CDCs (SCD type 1 & 2); Job Workflows and various data orchestration patterns.·6 min read·Jul 6, 2022--3--3
PinnedProsenjit Chakraborty4 more MV Time Series Forecasting we should know — Auto_ARIMA, SARIMAX, VARMAX & ProphetMultivariate Time Series Forecasting using Auto_ARIMA, SARIMAX, VARMAX & Prophet·6 min read·May 23, 2022--3--3
PinnedProsenjit ChakrabortyMultivariate Time Series Forecasting using Vector AutoRegressionStep by step approach on using Vector AutoRegression method on a multi-variate time series dataset.·5 min read·Feb 20, 2022----
Prosenjit ChakrabortyMicrosoft Fabric — exploring the Data Engineering ServicesMicrosoft Fabric — exploring various Data Engineering services & constructing a comprehensive Data Architecture utilizing Fabric…·7 min read·Jul 4, 2023----
Prosenjit ChakrabortyUnleashing the Power of Databricks & Azure Synapse Analytics Spark Optimization TechniquesListing the various Spark optimizations techniques available with Databricks & Azure Synapse Analytics.·6 min read·Jun 12, 2023----
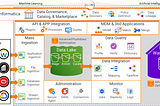
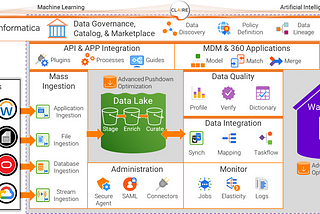
Prosenjit ChakrabortyEmpowering your Cloud Data Pipeline with Informatica IICS DI, DQ, and MDMExploring how Informatica IICS DI, DQ, and MDM can help organizations overcome common challenges in cloud data pipeline management…·8 min read·Apr 18, 2023--1--1
Prosenjit ChakrabortyPandas to PySpark conversion — how ChatGPT saved my day!My experience with ChatGPT for converting Pandas code to PySpark.·6 min read·Mar 28, 2023--2--2
Prosenjit ChakrabortyNavigating GCP’s Data Processing Pipeline OptionsFeature comparisons with sample architectures of GCP’s data pipeline services — Cloud Dataflow, Cloud Data Fusion & Cloud Composer.·5 min read·Mar 4, 2023----